Compressione in frequenza il Sound Recover della Phonak (AG).
La compressione in frequenza si verifica quando la banda del segnale di ingresso è compressa in una ristretta banda di uscita. Alcuni studi identificano due tipi di compressione in frequenza, quella lineare e quella non lineare. La compressione lineare prevede un rapporto tra frequenza di ingresso e frequenza di uscita di tipo proporzionale. In questo caso tutte le frequenze sono spostate verso il basso dello stesso fattore moltiplicativo (McDermott & Dean, 2000; Turner & Hurtig, 1999). In quella non lineare lo spostamento avviene solo per le frequenze sopra una soglia predeterminata. I segnali sotto questa soglia non sono compressi mentre quelli sopra lo sono con un rapporto prestabilito (Simpson et al., 2005). Attualmente la compressione in frequenza di tipo lineare non è ancora stata implementata in un AA (Simpson, 2009). Per quanto riguarda la compressione non lineare la Phonak rappresenta l’unica azienda produttrice al mondo ad avere sviluppato ed implementato nella sua gamma di AA un algoritmo capace di svolgere questa funzione. L’immagine successiva mostra come i segnali sono elaborati dall’algoritmo di compressione in frequenza Sound Recover.
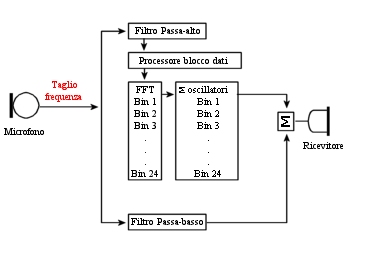
Schema di funzioneameto del Sound Recover della Phonak.
Lo schema illustra come i filtri passa-basso e passa-alto processano il segnale di ingresso in modo indipendente prima di essere ricomposti ed inviati come segnale di uscita al ricevitore. E’ possibile programmare due parametri distinti che definiscono il modo in cui la compressione in frequenza è applicata al segnale di ingresso. Il primo rappresenta la frequenza di taglio (FT), cioè la frequenza che separa la banda trattata dal filtro passa-basso e quella trattata dal filtro passa-alto. Il secondo rappresenta il rapporto di compressione, ovvero la quantità di compressione calcolata dal rapporto tra la larghezza di banda di ingresso e quella di uscita.
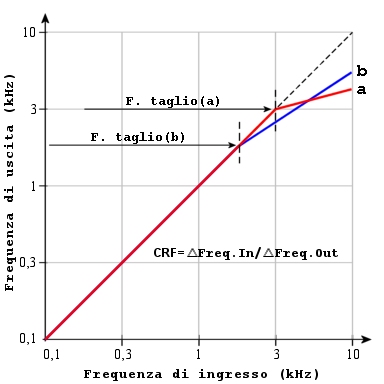
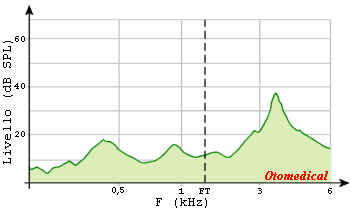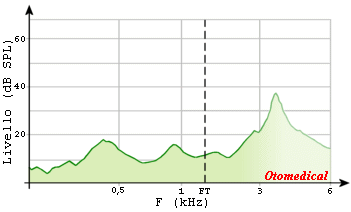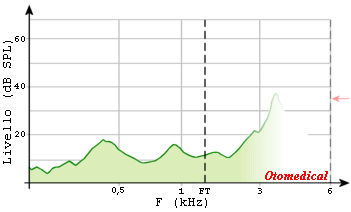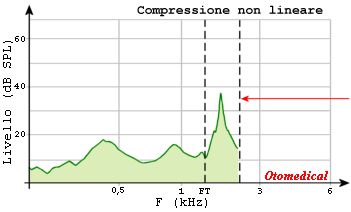
Compressione non lineare in frequenza.
Curva (a): F.taglio 3.000 Hz elevato CRF, settaggio indicatio nelle ipoacusie moderate in discesa.
Curva (b): F.taglio 1.500 Hz minore CRF, settaggio indicato nelle ipoacusie gravi, severe e pantonali.
Il grafico illustra l’effetto della modifica dei due parametri sulla angolazione della compressione non lineare in frequeza. Il settaggio indicato nelle ipoacusie moderate in discesa prevede una frequenza di taglio impostata a 3.000 Hz e un elevato rapporto di compressione curva (a). Nelle ipoacusie gravi severe e pantonali è indicata una frequenza di taglio a 1.500 Hz e un rapporto di compressione meno elevato curva (b). In entrambi i casi i suoni più distanti dall’ultima frequenza più acuta udibile, sono compressi maggiormente rispetto a quelli più vicini permettendo l’ampliamento artificiale del range uditivo frequenziale senza sovrapposizioni di frequenza.
Compressione non lineare in frequenza Sound Recover. Solo le frequenze acute sono compresse a partire dalla frequenza di taglio FT.
La gestione del guadagno delle frequenze trasposte avviene nel modo tradizionale. Il rapporto di compressione e la frequenza di taglio sono calcolati automaticamente dal software di fitting in base all’ipoacusia e all’età del paziente, tuttavia se necessario è possibile apportare modifiche o disattivare l’algoritmo. Le frequenze sotto il ginocchio di intervento della trasposizione non subiscono nessuna alterazione. L’algoritmo di compressione in frequenza è costantemente attivo e non provoca nessuna sovrapposizione del segnale di uscita tra le frequenze compresse nella banda passa-alto e quelle non compresse nella banda passa-basso. Nessuna analisi in frequenza del segnale di ingresso è richiesta. L’immagine seguente mostra l’analisi spettrale della parola /ASA/.
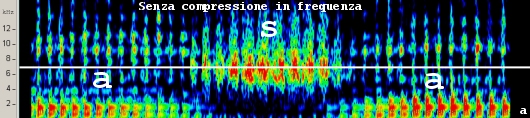
Distribuzione energetica reale della parola /asa/: Lo spettrogramma evidenzia la maggiore energia della lettera /s/ sulle frequenze acute.
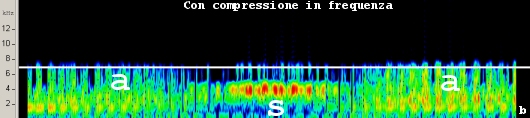
Distribuzione energetica reale della parola /asa/: Spettrogramma con Sound Recover attivo: la lettera /s/ è compressa in un range frequenziale più basso.
Lo spettrogramma evidenzia la distribuzione energetica sulle alte frequenze della lettera /S/ in funzione del tempo. Lo stesso fonema è analizzato attivando la compressione non lineare in frequenza. Lo spettrogramma mostra l’effetto della compressione sulle sole componenti in alta frequenza della lettera /S/. Gli studi indicano che l’uso della compressione in frequenza migliora la percezione dei suoni deboli in ambienti quieti e la discriminazione del parlato in presenza di rumore. I test eseguiti dimostrano anche che il paziente ottiene risultati apprezzabili solo dopo quattro settimane dall’adattamento iniziale.

Leave A Comment
You must be logged in to post a comment.